在Ubuntu24.04上运行Qwen2.5大模型
思路:
- 使用
ollama安装运行各种大模型,这里选择的是Qwen2.5 - 使用
Open WebUI作为前端聊天界面 - 整个后端和前端使用一个
docker compose文件来安装、控制
运行环境
OS : Ubuntu24.04
CPU : 13700k
显卡 :RTX3090 24G显存
项目地址:
使用的是这个github项目库
准备工作
安装
安装nvidia container toolkit
1 | sudo apt update |
克隆项目库
1 | git clone https://github.com/valiantlynx/ollama-docker.git |
此项目库里有2个docker compose文件:
- docker-compose-ollama-gpu.yaml
- docker-compose.yml
docker-compose.yml文件是没有GPU加速功能的,把它删除掉,并且把docker-compose-ollama-gpu.yaml这个文件改名为docker-compose.yml。
1 | rm docker-compose.yml |
运行docker
1 | docker-compose up -d |
这样,会自动下载ollama和Open WebUI。
安装完成后,打开http://localhost:8000,并进行后续设置
设置Open WebUI
点击右上角图标,选择管理员面板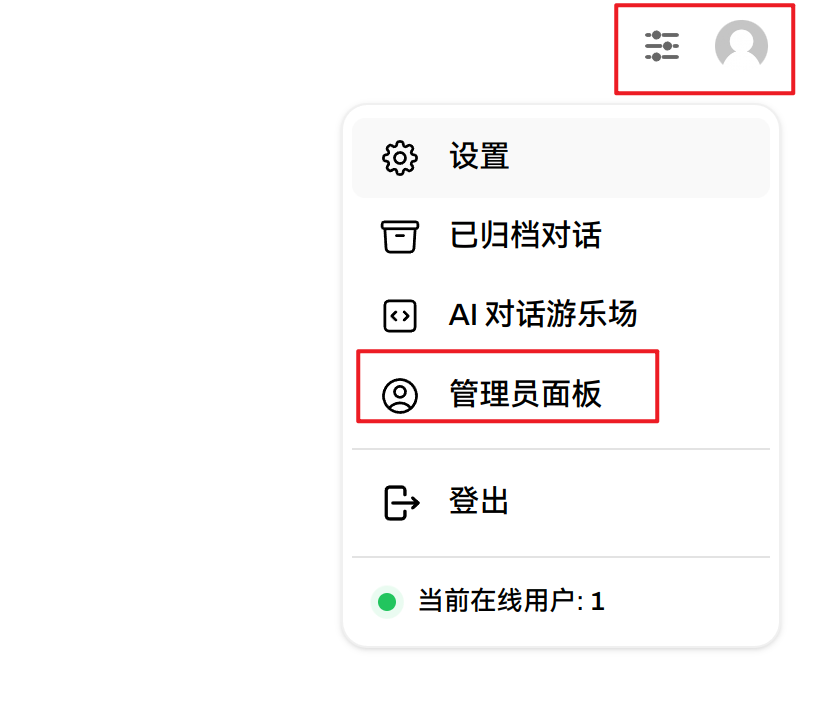
选择设置–模型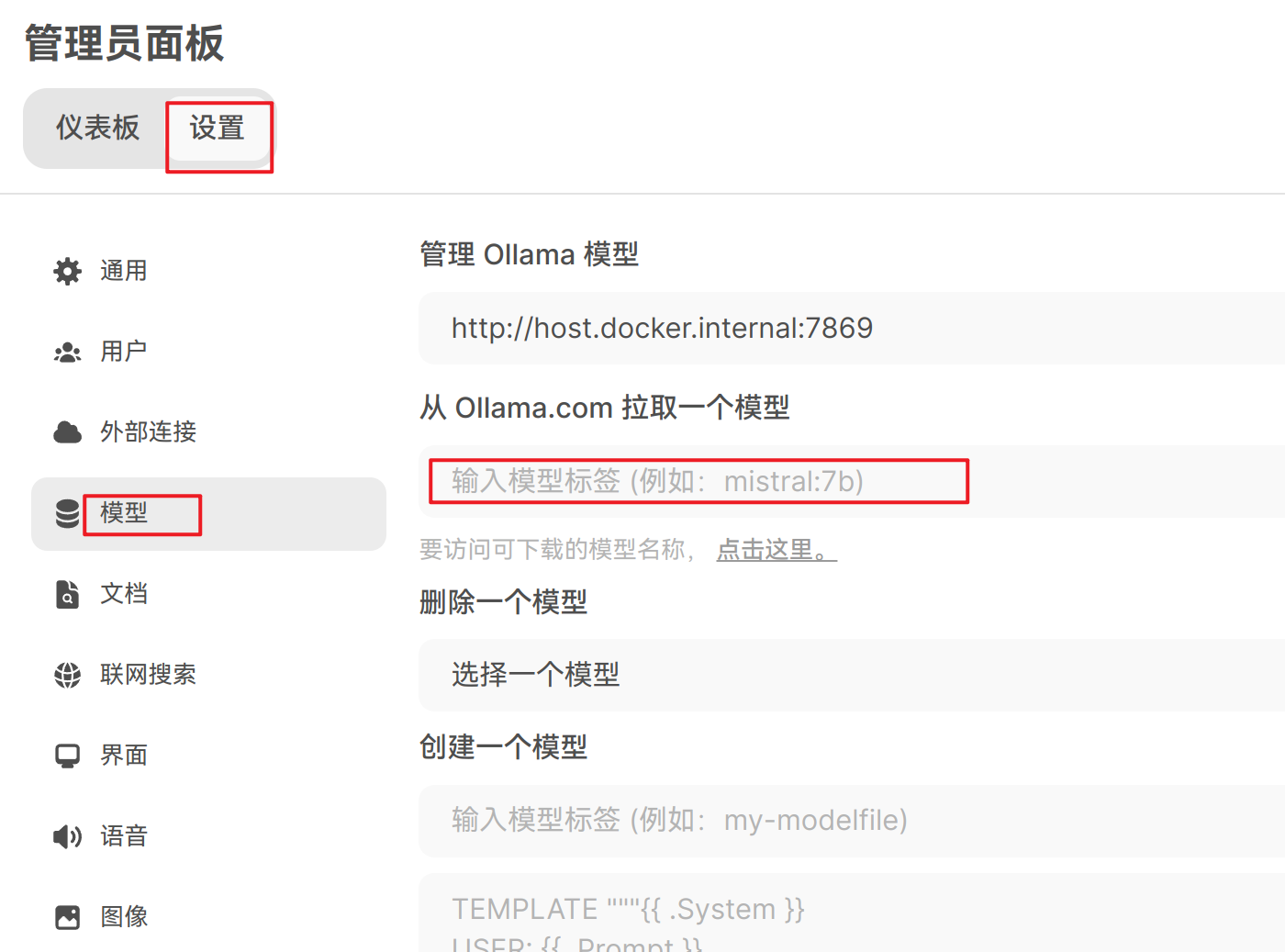
在从 Ollama.com 拉取一个模型里,输入qwen2.5:32b,这样会自动下载模型。
为什么要选择
qwen2.5:32b这个模型呢?是因为32b的大小20G,正好在 RTX 3090 24G显存的范围内。而且经我实测,效果非常好。
通过docker compose这种方式安装,已经设置好了,可以从局域网内其它电脑上访问服务,这一点很方便。
至此,所有工作都已完成,愉快的和AI模型对话吧。